
玩遍 MLIR - Part 0. MLIR Introduction
MLIR 是一個開源編譯器的框架,也是一套完整的 toolbox,MLIR 深受 LLVM 影響,和 LLVM 的精神是一樣的,全名叫做 Multi-Level Intermediate Representation,這年頭聽到 ML 都會認為是 Machine Learning,不過有趣的是,MLIR 的確是為了機器學習而生,真的是美麗的巧合😉,在本篇會介紹 MLIR 概念以及目前有名的深度學習框架 tensorflow,之後的文章會利用官網上的教學來建出一個編譯器。
# 一、MLIR 簡介
# 1-1. 什麼是 MLIR
MLIR 其實就跟 LLVM 一樣,是一個開源編譯器的框架,有了它們,其實你可以很方便的建立出可重用跟可擴展的編譯器。主要目標為
處理軟硬體多樣性造成的碎片化問題
當今最大的挑戰之一,即是市場上許多不同的解決方案。看似永無止境的軟體選項與硬體架構清單,造成碎片化生態系統的擴大。讓終端到雲端的擴充性變得十分困難,對於開發人員以及新技術的採用也更為挑戰。效能與效率的強烈需求,意謂著共同架構的必要性,才能讓設計與部署更為便利。當然 MLIR 是用來處理和LLVM 所解決的相似開發上的問題,這個等一下會提到。
支持異構的編譯,那什麼是異構計算 ?
摩爾定律的極限
根據半導體的從業人員奉為圭臬的「摩爾定律(Moore’s Law)」,便預言每十八個月積體電路上所能容納的電晶體個數,就能變為原來的兩倍,而且成本不變。這使得人們有機會每隔十八個月用同樣的價錢,買到兩倍計算效能的電腦。不過,即使摩爾定律在過去幾十年來如此準確,在短期內看起來也會依然有效,但是,還是開始有愈來愈多的人預言摩爾定律的時代即將結束。摩爾定律被預言即將結束的原因像是,半導體終有其物理極限,以及隨著技術不斷精進,需要的研發投資愈來愈高等等。
異質計算的出現
隨著近年來矽晶片逼近物理的極限和經濟成本高升,摩爾定律已趨近失效。使用通用處理器 CPU 這個傳統的方法已無法滿足AI的各種應用對爆發的和高計算能力的需求。因此,具有GPU、ASIC、FPGA或其它加速器(Accelerator)等高度平行、高密集的計算能力的異質計算持續發光發熱,而異質計算也將成為支撐先進和以後更複雜AI 應用的必然的選擇。
異質計算(Heterogeneous Computing)是指使用不同類型指令集和體系架構的計算單元組成的計算系統,同台電腦有不同指令集的硬體設備,例如 GPU 跟 CPU。異構計算是性能、成本和功耗均衡的技術,同時也是讓最適合的專用硬體去做最適合的事如密集計算或外設管理等,從而達到性能和成本的最優化。
編譯器的重要性
因為硬體資源的極限,我們需要妥善的規劃、最佳化我們的指令來達到最佳化硬體使用率的功用,例如 指令流水線(pipeline)技術、亂序執行(out-of-order execution)等。同台電腦但是不同指令集架構的 CPU、GPU。我們需要編譯器幫我們產生、最佳化對應指令集的程式碼,才能在有限的資源中榨出更高的效能。
減少特定領域語言(domain-specific language, DSL)編譯器的開發成本,那什麼是特定領域語言 DSL (Domain-specific language) ? 為什麼要使用領域特定語言?
「domain-specific languages」可以泛指任何特定領域的語言,基本思想是一種針對特定類型問題的計算機語言。例如 UML、XML,甚至連 C#、Java 都算是特定領域的語言,因為它們都是針對特定目的、(軟體開發),用於特定場合的語言,這是比較廣義的看法。不過,就軟體開發這塊領域而言,UML、C#、Java 可運用於各類型的軟體開發,所以我們通常將它們視為通用目的語言。DSL 只用在某些特定的領域。比如用來顯示網頁的HTML,以及 Emacs 所使用的 Emac LISP 語言、描述建置軟體的 make、ant 和 rake,或者用於建構語言的 lexx 和 yacc、甚至是查詢語言(SQL、XPath 等)、所有模板語言(Django、Smarty 等)、shell 腳本、資料儲存和交換語言(XML、YAML 等),以及 LaTex、或 CSS 等語言。使用 DSL,通過隱藏技術細節,DSL 可以讓使用者適應系統,而無需太多技術開發人員。它可以更輕鬆地與開發人員、經理、客戶或最終用戶等交談。
所以,因為異構計算的興起及硬體的多樣性,造就這些用來描述圖的 IR / DSL 多樣的編譯生態,使得開發整合上常常出現問題,所以才需要 MLIR 來解決這些問題,與 LLVM 解決傳統編譯器的開發整合問題有異曲同工之妙,Google 在 MLIR 設計上也參照了不少 LLVM 的精神及理念。
# 1-2. 參考連結
- 開發人員的逆襲: Domain-Specific Languages (opens new window)
- DSL - Domain Specific Language 簡介 (opens new window)
- 異構計算─ 分而治之的平行計算 (opens new window)
# 二、MLIR 跟 Tensorflow
| 深度學習框架 | Tensorflow 2.0 Icon |
|---|---|
 | Tensorflow 是目前世界上最有名的深度學習框架之一,由 Google 開發,可以幫助我們建立出完整的神經網路。 |
# 2-1. 的執行方式 - 計算圖
在深度學習模型中,一般都是用計算圖來表示節點之間的運算關係以及定義整個神經網路的架構。符號式的計算圖結構,可以將數學表現式與真正的資料內容分離,而使原始碼更為近似於紙筆的理論推導

使用計算圖表示神經網路,有幾個優點
可讀性
令類神經網路的理論建構者,能更輕鬆的編寫直覺式的程式碼,也增加了原始碼的易讀性。
平行計算
需要耗費許多運算能力的梯度運算,藉由封裝成計算圖中運算元裡的屬性,在執行計算圖時,根據運算元的特性,在執行期間分散到不同的設備上,如分配到不同 GPU、不同主機等,平行化運算是最大的好處,由上圖可以知道加法跟乘法互不相干、彼此獨立,所以我們可以利用圖的拓樸去進行運算資源的分配,以最有效的方式執行計算圖。
可攜性
計算圖的表示和 IR 一樣獨立於程式語言與平台的程式瑪。想要藉由計算圖恢復成任何程式語言的表示是可行的。
計算圖又分為動態計算圖(dynamic computational graph)和靜態計算圖(static computational graph)。
PyTorch 以動態計算圖來建構神經網路,在執行時動態微分(runtime autodiff),這樣的方式有利於直譯式語言,去動態執行計算圖中的每一個子圖中的運算,並及時得到運算的結果。
Tensorflow 以靜態計算圖來建構神經網路,為事先自動微分(ahead-of-time audodiff)。因為已知計算流程都已透過計算圖表達,所以編譯器可以針對圖形中的單一運算元,甚至整張子圖做優化。除此之外,對於異質計算環境(包括 GPU 和 CPU),可以先行配置運算元到能達到最佳利用的設備,而完成有效地分散和平行運算。
# 2-2. Tensorflow 執行計算圖的流程
首先參考下面這張圖,闡述了 tensorflow 的執行精隨。
| 圖一 | 圖二 |
|---|---|
 |  |
首先我們先用不同的程式語言,去建構 tensorflow 計算圖模型出來,當要執行計算圖模型時,上圖的最右側是 tensorflow runtime,有兩個元件,一個是執行器(Executor),用來執行計算圖運算的,當碰到每一個節點時,都會去查詢另一個元件 Kernel,然後找到合適的 kernel,然後在執行對應的運算。

當我們用程式語言去定義計算圖後,tensorflow 有一個圖的最佳化工具名為 Grappler,去簡化圖以及一些最佳化的處理,可以更有效率的跑在大多數的硬體架構上。
::: info 什麼是 op ? 什麼是 kernel ? 源自 深度學習框架隨想(一):Op與Kernel (opens new window)
- Kernel 其實就是對 Tensor 進行操作的一個函數,一段計算邏輯,Tensor In Tensor Out,是具體的計算、實現方法(近看)。
- Op 就是 Kernel 的集合,一個Op代表的是有一定共性的多個 Kernel,其實就是 kernel 的抽象化,是概念、我們一般人所看到的運算(遠看)。
雖然在計算圖上我們是用Op來表示一個個的節點,但實際上,計算圖上的每個節點代表的一個Kernel 。因為在計算圖上我們除了存儲Op本身的配置屬性之外,還存儲了一些額外的屬性(如Device、DataType等)。基於Op的配置和這些額外的配置,我們可以確切的為每個節點找到唯一一個對應的 Kernel。Graph 節點代表操作 Ops(例如 Add、MatMul、Conv2D 等)。這代表抽象的設備、執行後端和語言無關的 API。 Graph 反過來由用 C++ 編寫的 Op Kernels 實現,專門用於 <Type, Device> 平台。
會有這層抽象化有兩個原因
從程式設計的角度
在 TensorFlow 中,
MatMulop 對應的 kernel 是class MatMulOp<Device, T, USE_CUBLAS>。這個模板類別的每一個全特化對應的都是一個真正的kernel,所以在MatMulop 這個概念之下,其實有針對不同的 kernel 進行特化,要用到哪種 kernel 編譯器再去實例化。 (模板真的要學好😂),例如CPU 實現的針對於 float 資料類型的 kernel(
MatMulOp<kCPU, float, false>)GPU 上使用 cublas 實現的針對 float 的 kernel(
MatMulOp<kGPU, float, true>)GPU 上不用 cublas 實現的針對 half 資料類型的 kernel(
MatMulOp<kGPU, half, false>)
簡化圖分析的複雜度
為了簡化圖分析的複雜性,我們按照某種規則去合併多個 Kernel,並在圖分析時把多個Kernel看作一個,命名為 Op,有利於之後最佳化的工作。
順道一提,有可能 op 還會特化出更多 op,再特化不同的 kernel,這就要看工程師如何去設計。例如 :
- 我們可以把
Conv1D、Conv2D和Conv3D共 3 個 op 合併成一個Convop,再讓使用者決定要用哪一種卷機運算。 Conv2Dop 拆成很多個 op,例如CpuConv2D,GpuConv2D,CpuConv2DForFloat,GpuConv2DForHalf等等,使得每個 op 都只對應更少(甚至只有一個)kernel。
因此,op 就像是一個抽象化的概念,簡化圖的分析複雜度,而再深入一點看,每個節點都是特化的 kernel,定義著運算方法、運算型態。而我們的 TensorFlow executor 會根據硬體架構去執行這些 op-kernel,如上所述,在 CPU、GPU 有不同的特化與實作。 :::
# 2-3. 頭痛的轉換工作
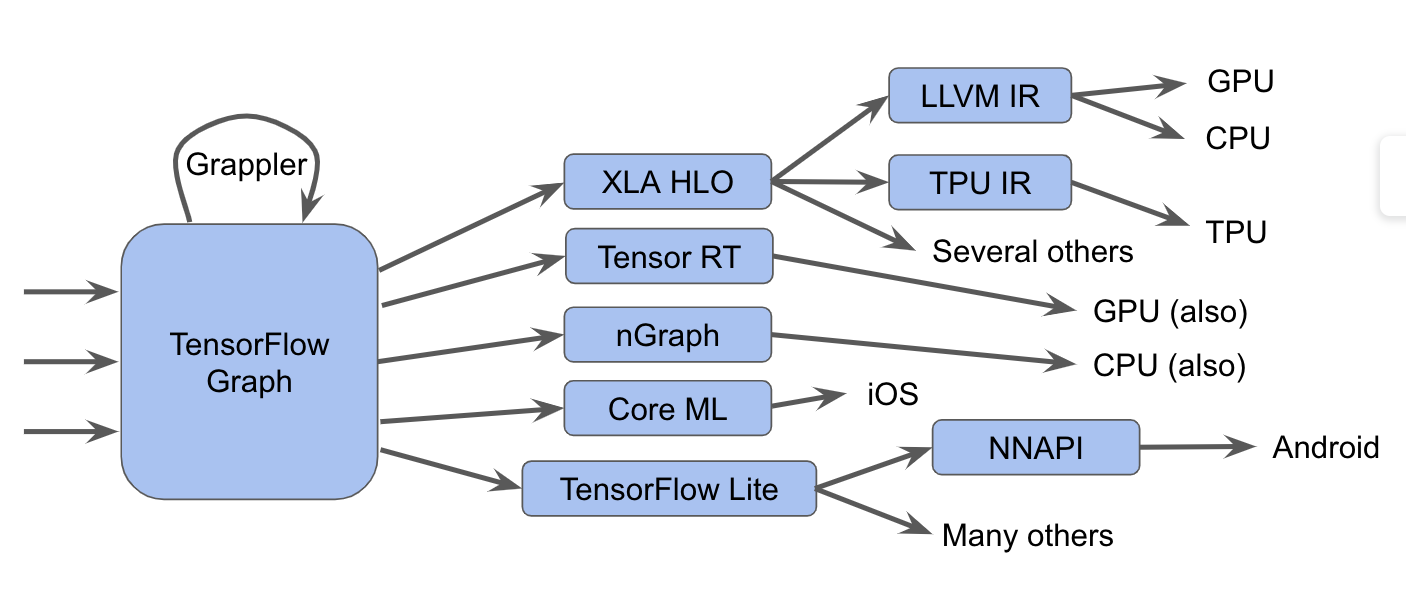
上圖是 tensorflow 的計算圖編譯生態系統 實際上更加複雜 ,包含了不同種編譯器跟最佳化器,會在軟體到硬體間進行多層(Multi-levle) 的最佳化,有時在不同層級之間的轉換時,會遇到一些令人費解的編譯器錯誤或是執行期錯誤,稍後會提到。如同上圖,TensorFlow graphs 會以不同方式執行計算。
如 2-2 小節所述,把計算圖送到 TensorFlow executor 根據節點去執行 kernel 運算。
把計算圖轉成
XLA High-Level Optimizer representation (XLA HLO),再利用 LLVM 轉成 CPU、GPU 的指令集架構,或是直接繼續使用產生 TPU 的指令集架構。把計算圖轉成
Tensor RT、nGraph表示型,再透過編譯器轉成特定硬體架構指令。把計算圖轉成
tensorflow lite格式,可以用 TensorFlow Lite runtime 去執行此計算圖。或者通過 Android 神經網絡 API(NNAPI)或相關技術將其進一步轉化,以在 GPU 或 DSP 上運行。
當然,也存在更複雜的路徑,像是使用 Grappler 進行神經網路每層的最佳化,去最佳化計算圖。
我們需要我們需要將神經網路的模型編譯到不同的硬體設備上,XLA HLO、Tensor RT、nGraph、Core ML、TensorFlow Lite 這幾種 IR (或 DSL,因為是用來描述計算圖模型的) 雖然相似、但仍然是不同的 IR,我們以其中一種轉化格式XLA HLO為例。

這種生態的問題在於基於圖的 IR 跟 基於 Three address 的 IR 是截然不同的,兩者鴻溝太大導致
一個基於圖的 IR 就要重複實現不同的 Three address 的 IR 轉化方式,組合爆炸且無法重用。
兩者 IR 的最佳化方法不能進行統一的最佳化工作,因為一個是計算圖的最佳化,一個是程式碼的最佳化。
XLA HLO 翻譯到 LLVM IR 相差太多,實現轉換開銷太大。
雖然這些眾多的編譯器和表示實現顯著提高了性能,但是對於新的軟體層 IR 或硬體指令集架構,需要為每一條新的路徑重新實現最佳化以及轉化的工作,除了無法重用的問題,轉換的問題,我們還要針對不同的計算圖 IR 格式進行各自的最佳化及設計。,如果你對 LLVM 有一點熟悉的話,會覺得這個問題很眼熟。沒錯,就是傳統編譯器有遇到的問題,耦合性太高,組合爆炸且無法重用,因此 LLVM IR 的出現統一了此亂象,而參照 LLVM IR, MLIR 就誕生了。
這一小節是參照 MLIR: A new intermediate representation and compiler framework (opens new window),文中所提到的 Hardware / software stack 指的是深度學習模型從軟體層到硬體層,層層的編譯、最佳化、轉換,如下表。
| 圖一 | 圖二 |
|---|---|
 |  |
所以當有新的軟體層 IR 產生,或是新的硬體指令集架構產生,從計算圖開始又要重新打造一系列的編譯、最佳化工作,這個成本著實可觀。
# 2-4. IR 群雄割據,MLIR 統一天下
從原始程式碼到目標程式碼,要經過一系列的抽像以及分析,通過 Lowering Pass 來實現從一個 IR 到另一個 IR 的轉換,這樣的過程中會存在有些行為重複實現的情況,也就導致了轉換效率低的問題。通俗的說,不同 IR 沒有默契。因為語言不通,為了解決這種亂象,MLIR 學 LLVM 一樣,統一了 IR,讓不同的 IR 可以藉由這個統一的 IR 相互理解。而 MLIR 利用 Dialect(方言),讓每個 IR 學習這個方言,大家就可以順利的互相溝通了。 和 LLVM 一樣,一統編譯器開發的亂象。
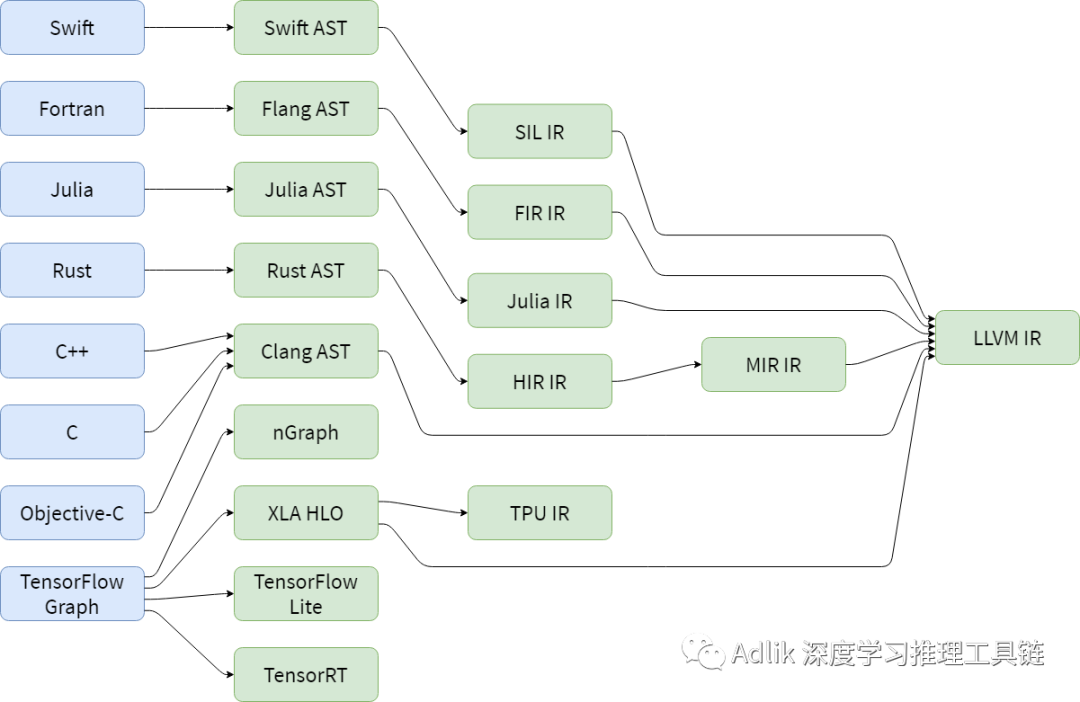
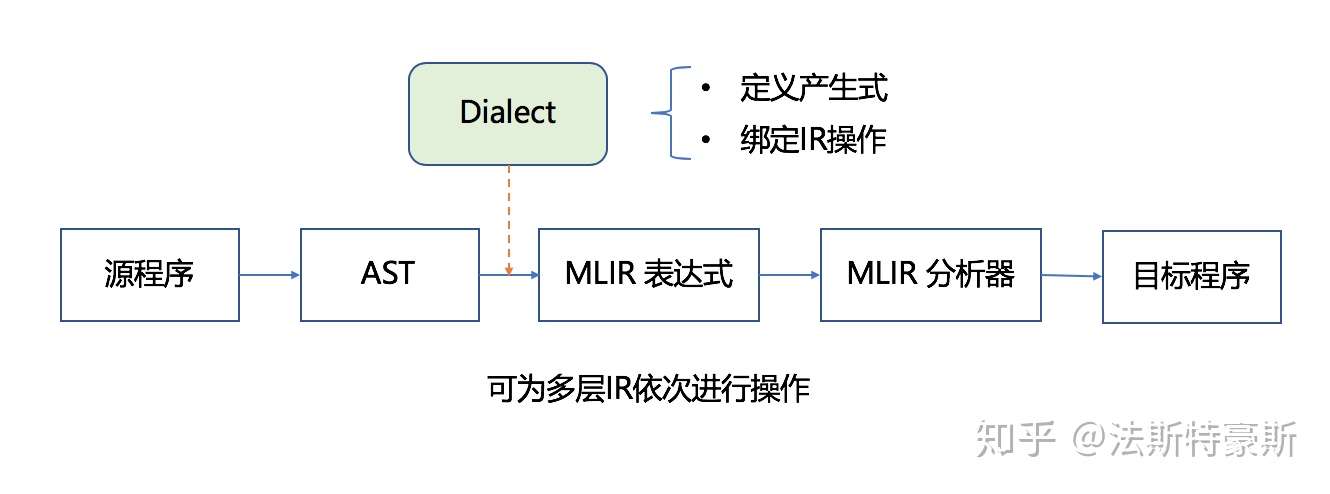
Dialects 就是 MLIR 的方言,我們可以定義很多不同的方言來表示不同的抽象,例如: 先把 tensorflow graph 翻譯成用 tensorflow dialect 描述的 MLIR 的檔案。得到 MLIR 的檔案後,tensorflow dialect 再轉成 HLO Dialect,再進行逐級向下抽象 (Multi-Level 的真意),每一個 pass 可以對某個部分進行最佳化,得到 LLVMIR Dialect,最後再轉換成真正的 LLVM IR 進行後續的處理。不同的方言也可以互相轉換,因為都是在同一個 MLIR 的規範下。Dialects是將所有的IR放在了同一個命名空間中,分別對每個IR定義對應的產生式以及綁定相應的操作,從而生成一個 MLIR 的模型。整個的編譯過程,從原始程式碼生成AST,借助 Dialects 遍歷 AST,產生 MLIR 的表達式,此處可為多層 IR 通過 Lowering Pass 依次進行分析,最後經過 MLIR 分析器,生成目標程式碼。MLIR 支持此種插件架構,可以使用它擴展幾乎所有 MLIR 功能。
| MLIR Dialect 的作用處 | MLIR Dialect 流程圖 |
|---|---|
 |  |